

ReCaptcha: Artificial AI
Here is a great two-fer. One action achieves two important tasks. This cool tool is a captcha that stops spam while digitizing books.
The captcha comes from Carnegie Mellon U. and does the usual job of filtering out bot postings on the web. Like other captchas it requires you to type in a distorted word you see in order to “prove” that you are a human, and not a computer script who will simply fill the comments with advertising spam. This filter works because computers are net yet able to read distorted text. Someday soon they will, of course, but for now we assume that anyone who can pass this simple reading test is a human.
But one of the persistent hurdles in the great effort to digitize books is distorted text on many scanned pages of old books — text which cannot be read by a computer. The computer software can read most of the words, but it gets stuck on a few that are blurry or ragged on the scan. Since this is precisely the problem that captchas solve, the genius idea is to combine the complementary problem and solution to do double duty. Send the distorted words in books to the captcha engines on web sites. Have the millions of eager commenters solve the hard digitizing problems.
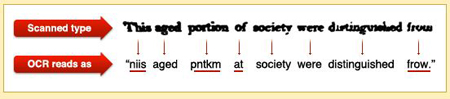
ReCaptcha web site says:
About 60 million CAPTCHAs are solved by humans around the world every day. In each case, roughly ten seconds of human time are being spent. Individually, that’s not a lot of time, but in aggregate these little puzzles consume more than 150,000 hours of work each day. What if we could make positive use of this human effort? reCAPTCHA does exactly that by channeling the effort spent solving CAPTCHAs online into “reading” books.
So how does it work? You type in two distorted words.
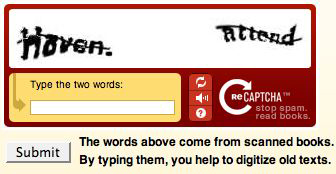
Why two? The official answer:
If a computer can’t read such a CAPTCHA, how does the system know the correct answer to the puzzle? Here’s how: Each new word that cannot be read correctly by OCR is given to a user in conjunction with another word for which the answer is already known. The user is then asked to read both words. If they solve the one for which the answer is known, the system assumes their answer is correct for the new one. The system then gives the new image to a number of other people to determine, with higher confidence, whether the original answer was correct.
This novel system is another example of using what Amazon’s Jeff Bezos calls “artificial artificial intelligence.” It fakes AI by using humans. This is how he sees his Mechanical Turk system which performs similar tasks for businesses. Humans are paid a few cents to do very simple — almost dumb — perception tasks that not even the fastest super computer can do. Recognizing the best picture of something, or matching names. Google’s image labeler is in the same category using volunteers en-masse to give a one word description to a picture by matching words that other volunteers give. When Google gets a matching word it assumes the word is a valid description of that image. Pretty soon, after millions of matches, you have an emerging database of descriptions which can train your automatic image recognizer.
And that is another function of what this CMU captcha could do, although it is not mentioned. It’s possible that this “artificial AI” process could train a software program to get much better at recognizing the distorted letters, so it would not need its human counterparts someday. It’s like having a million nannies gently correct the toddling AI.
Oh, the books in the CMU ReCaptcha are being served up by the Internet Archive, a great humanitarian campaign to digitize public domain books, an effort worth supporting.
This is so cool, I am going to try to implement it on my websites.