

Evidence of a Global SuperOrganism
I am not the first, nor the only one, to believe a superorganism is emerging from the cloak of wires, radio waves, and electronic nodes wrapping the surface of our planet. No one can dispute the scale or reality of this vast connectivity. What’s uncertain is, what is it? Is this global web of computers, servers and trunk lines a mere mechanical circuit, a very large tool, or does it reach a threshold where something, well, different happens?
So far the proposition that a global superorganism is forming along the internet power lines has been treated as a lyrical metaphor at best, and as a mystical illusion at worst. I’ve decided to treat the idea of a global superorganism seriously, and to see if I could muster a falsifiable claim and evidence for its emergence.
My hypothesis is this: The rapidly increasing sum of all computational devices in the world connected online, including wirelessly, forms a superorganism of computation with its own emergent behaviors.
Superorganisms are a different type of organism. Large things are made from smaller things. Big machines are made from small parts, and visible living organisms from invisible cells. But these parts don’t usually stand on their own. In a slightly fractal recursion, the parts of a superorganism lead fairly autonomous existences on their own. A superorganism such as an insect or mole rat colony contains many sub-individuals. These individual organisms eat, move about, get things done on their own. From most perspectives they appear complete. But in the case of the social insects and the naked mole rat these autonomous sub individuals need the super colony to reproduce themselves. In this way reproduction is a phenomenon that occurs at the level of the superorganism.
I define the One Machine as the emerging superorganism of computers. It is a megasupercomputer composed of billions of sub computers. The sub computers can compute individually on their own, and from most perspectives these units are distinct complete pieces of gear. But there is an emerging smartness in their collective that is smarter than any individual computer. We could say learning (or smartness) occurs at the level of the superorganism.
Supercomputers built from subcomputers were invented 50 years ago. Back then clusters of tightly integrated specialized computer chips in close proximity were designed to work on one kind of task, such as simulations. This was known as cluster computing. In recent years, we’ve created supercomputers composed of loosely integrated individual computers not centralized in one building, but geographically distributed over continents and designed to be versatile and general purpose. This later supercomputer is called grid computing because the computation is served up as a utility to be delivered anywhere on the grid, like electricity. It is also called cloud computing because the tally of the exact component machines is dynamic and amorphous – like a cloud. The actual contours of the grid or cloud can change by the minute as machines come on or off line.
There are many cloud computers at this time. Amazon is credited with building one of the first commercial cloud computers. Google probably has the largest cloud computer in operation. According to Jeff Dean one of their infrastructure engineers, Google is hoping to scale up their cloud computer to encompass 10 million processors in 1,000 locations.
Each of these processors is an off-the-shelf PC chip that is nearly identical to the ones that power your laptop. A few years ago computer scientists realized that it did not pay to make specialized chips for a supercomputer. It was far more cost effective to just gang up rows and rows of cheap generic personal computer chips, and route around them when they fail. The data centers for cloud computers are now filled with racks and racks of the most mass-produced chips on the planet. An unexpected bonus of this strategy is that their high production volume means bugs are minimized and so the generic chips are more reliable than any custom chip they could have designed.
If the cloud is a vast array of personal computer processors, then why not add your own laptop or desktop computer to it? It in a certain way it already is. Whenever you are online, whenever you click on a link, or create a link, your processor is participating in the yet larger cloud, the cloud of all computer chips online. I call this cloud the One Machine because in many ways it acts as one supermegacomputer.

The majority of the content of the web is created within this one virtual computer. Links are programmed, clicks are chosen, files are moved and code is installed from the dispersed, extended cloud created by consumers and enterprise – the tons of smart phones, Macbooks, Blackberries, and workstations we work in front of. While the business of moving bits and storing their history all happens deep in the tombs of server farms, the cloud’s interaction with the real world takes place in the extremely distributed field of laptop, hand-held and desktop devices. Unlike servers these outer devices have output screens, and eyes, skin, ears in the form of cameras, touch pads, and microphones. We might say the cloud is embodied primarily by these computer chips in parts only loosely joined to grid.
This megasupercomputer is the Cloud of all clouds, the largest possible inclusion of communicating chips. It is a vast machine of extraordinary dimensions. It is comprised of quadrillion chips, and consumes 5% of the planet’s electricity. It is not owned by any one corporation or nation (yet), nor is it really governed by humans at all. Several corporations run the larger sub clouds, and one of them, Google, dominates the user interface to the One Machine at the moment.
None of this is controversial. Seen from an abstract level there surely must be a very large collective virtual machine. But that is not what most people think of when they hear the term a “global superorganism.” That phrase suggests the sustained integrity of a living organism, or a defensible and defended boundary, or maybe a sense of self, or even conscious intelligence.
Sadly, there is no ironclad definition for some of the terms we most care about, such as life, mind, intelligence and consciousness. Each of these terms has a long list of traits often but not always associated with them. Whenever these traits are cast into a qualifying definition, we can easily find troublesome exceptions. For instance, if reproduction is needed for the definition of life, what about mules, which are sterile? Mules are obviously alive. Intelligence is a notoriously slippery threshold, and consciousness more so. The logical answer is that all these phenomenon are continuums. Some things are smarter, more alive, or less conscious than others. The thresholds for life, intelligence, and consciousness are gradients, rather than off-on binary.
With that perspective a useful way to tackle the question of whether a planetary superorganism is emerging is to offer a gradient of four assertions.
There exists on this planet:
- I A manufactured superorganism
- II An autonomous superorganism
- III An autonomous smart superorganism
- IV An autonomous conscious superorganism
These four could be thought of as an escalating set of definitions. At the bottom we start with the almost trivial observation that we have constructed a globally distributed cluster of machines that can exhibit large-scale behavior. Call this the weak form of the claim. Next come the two intermediate levels, which are uncertain and vexing (and therefore probably the most productive to explore). Then we end up at the top with the extreme assertion of “Oh my God, it’s thinking!” That’s the strong form of the superorganism. Very few people would deny the weak claim and very few affirm the strong.
My claim is that in addition to these four strengths of definitions, the four levels are developmental stages through which the One Machine progresses. It starts out forming a plain superorganism, than becomes autonomous, then smart, then conscious. The phases are soft, feathered, and blurred. My hunch is that the One Machine has advanced through levels I and II in the past decades and is presently entering level III. If that is true we should find initial evidence of an autonomous smart (but not conscious) computational superorganism operating today.
But let’s start at the beginning.
LEVEL I
A manufactured superorganism
By definition, organisms and superorganisms have boundaries. An outside and inside. The boundary of the One Machine is clear: if a device is on the internet, it is inside. “On” means it is communicating with the other inside parts. Even though some components are “on” in terms of consuming power, they may be on (communicating) for only brief periods. Your laptop may be useful to you on a 5-hour plane ride, but it may be technically “on” the One Machine only when you land and it finds a wifi connection. An unconnected TV is not part of the superorganism; a connected TV is. Most of the time the embedded chip in your car is off the grid, but on the few occasions when its contents are downloaded for diagnostic purposes, it becomes part of the greater cloud. The dimensions of this network are measurable and finite, although variable.
The One Machine consumes electricity to produce structured information. Like other organisms, it is growing. Its size is increasing rapidly, close to 66% per year, which is basically the rate of Moore’s Law. Every year it consumes more power, more material, more money, more information, and more of our attention. And each year it produces more structured information, more wealth, and more interest.
On average the cells of biological organisms have a resting metabolism rate of between 1- 10 watts per kilogram. Based on research by Jonathan Koomey a UC Berkeley, the most efficient common data servers in 2005 (by IBM and Sun) have a metabolism rate of 11 watts per kilogram. Currently the other parts of the Machine (the electric grid itself, the telephone system) may not be as efficient, but I haven’t found any data on it yet. Energy efficiency is a huge issue for engineers. As the size of the One Machine scales up the metabolism rate for the whole will probably drop (although the total amount of energy consumed rises).
The span of the Machine is roughly the size of the surface of the earth. Some portion of it floats a few hundred miles above in orbit, but at the scale of the planet, satellites, cell towers and servers farms form the same thin layer. Activity in one part can be sensed across the entire organism; it forms a unified whole.
Within a hive honeybees are incapable of thermoregulation. The hive superorganism must regulate the bee’s working temperature. It does this by collectively fanning thousands of tiny bee wings, which moves hot air out of the colony. Individual computers are incapable of governing the flow of bits between themselves in the One Machine.
Prediction: the One Machine will continue to grow. We should see how data flows around this whole machine in response to daily usage patterns (see Follow the Moon). The metabolism rate of the whole should approach that of a living organism.
LEVEL II
An autonomous superorganism
Autonomy is a problematic concept. There are many who believe that no non-living entity can truly be said to be autonomous. We have plenty of examples of partial autonomy in created things. Autonomous airplane drones: they steer themselves, but they don’t repair themselves. We have self-repairing networks that don’t reproduce themselves. We have self-reproducing computer viruses, but they don’t have a metabolism. All these inventions require human help for at least aspect of their survival. To date we have not conjured up a fully human-free sustainable synthetic artifact of any type.
But autonomy too is a continuum. Partial autonomy is often all we need – or want. We’ll be happy with miniature autonomous cleaning bots that requires our help, and approval, to reproduce. A global superorganism doesn’t need to be fully human-free for us to sense its autonomy. We would acknowledge a degree of autonomy if an entity displayed any of these traits: self-repair, self-defense, self-maintenance (securing energy, disposing waste), self-control of goals, self-improvement. The common element in all these characteristics is of course the emergence of a self at the level of the superorganism.
In the case of the One Machine we should look for evidence of self-governance at the level of the greater cloud rather than at the component chip level. A very common cloud-level phenomenon is a DDoS attack. In a Distributed Denial of Service (DDoS) attack a vast hidden network of computers under the control of a master computer are awakened from their ordinary tasks and secretly assigned to “ping” (call) a particular target computer in mass in order to overwhelm it and take it offline. Some of these networks (called bot nets) may reach a million unsuspecting computers, so the effect of this distributed attack is quite substantial. From the individual level it is hard to detect the net, to pin down its command, and to stop it. DDoS attacks are so massive that they can disrupt traffic flows outside of the targeted routers – a consequence we might expect from an superorganism level event.
I don’t think we can make too much of it yet, but researchers such as Reginald Smith have noticed there was a profound change in the nature of traffic on the communications network in the last few decades as it shifted from chiefly voice to a mixture of data, voice, and everything else. Voice traffic during the Bell/AT&T era obeyed a pattern known as Poisson distribution, sort of like a Gaussian bell curve. But ever since data from diverse components and web pages became the majority of bits on the lines, the traffic on the internet has been following a scale-invariant, or fractal, or power-law pattern. Here the distribution of very large and very small packets fall out onto a curve familiarly recognized as the long-tail curve. The scale-invariant, or long tail traffic patterns of the recent internet has meant engineers needed to devise a whole set of new algorithms for shaping the teletraffic. This phase change toward scale-invariant traffic patterns may be evidence for an elevated degree of autonomy. Other researchers have detected sensitivity to initial conditions, “strange attractor” patterns and stable periodic orbits in the self-similar nature of traffic – all indications of self-governing systems. Scale-free distributions can be understood as a result of internal feedback, usually brought about by loose interdependence between the units. Feedback loops constrain the actions of the bits by other bits. For instance the Ethernet collision detection management algorithm (CSMA/CD) employs feedback loops to manage congestion by backing off collisions in response to other traffic. The foundational TCP/IP system underpinning internet traffic therefore “behaves in part as a massive closed loop feedback system.” While the scale free pattern of internet traffic is indisputable and verified by many studies, there is dispute whether it means the system itself is tending to optimize traffic efficiency – but some believe it is.
Unsurprisingly the vast flows of bits in the global internet exhibit periodic rhythms. Most of these are diurnal, and resemble a heartbeat. But perturbations of internet bit flows caused by massive traffic congestion can also be seen. Analysis of these “abnormal” events show great similarity to abnormal heart beats. They deviate from an “at rest” rhythms the same way that fluctuations of a diseased heart deviated from a healthy heart beat.
Prediction: The One Machine has a low order of autonomy at present. If the superorganism hypothesis is correct in the next decade we should detect increased scale-invariant phenomenon, more cases of stabilizing feedback loops, and a more autonomous traffic management system.
LEVEL III
An autonomous smart superorganism
Organisms can be smart without being conscious. A rat is smart, but we presume, without much self-awareness. If the One Machine was as unconsciously smart as a rat, we would expect it to follow the strategies a clever animal would pursue. It would seek sources of energy, it would gather as many other resources it could find, maybe even hoard them. It would look for safe, secure shelter. It would steal anything it needed to grow. It would fend off attempts to kill it. It would resist parasites, but not bother to eliminate them if they caused no mortal harm. It would learn and get smarter over time.
Google and Amazon, two clouds of distributed computers, are getting smarter. Google has learned to spell. By watching the patterns of correct-spelling humans online it has become a good enough speller that it now corrects bad-spelling humans. Google is learning dozens of languages, and is constantly getting better at translating from one language to another. It is learning how to perceive the objects in a photo. And of course it is constantly getting better at answering everyday questions. In much the same manner Amazon has learned to use the collective behavior of humans to anticipate their reading and buying habits. It is far smarter than a rat in this department.
Cloud computers such as Google and Amazon form the learning center for the smart superorganism. Let’s call this organ el Googazon, or el Goog for short. El Goog encompasses more than the functions the company Google and includes all the functions provided by Yahoo, Amazon, Microsoft online and other cloud-based services. This loosely defined cloud behaves like an animal.
El Goog seeks sources of energy. It is building power plants around the world at strategic points of cheap energy. It is using its own smart web to find yet cheaper energy places and to plan future power plants. El Goog is sucking in the smartest humans on earth to work for it, to help make it smarter. The smarter it gets, the more smart people, and smarter people, want to work for it. El Goog ropes in money. Money is its higher metabolism. It takes the money of investors to create technology which attracts human attention (ads), which in turns creates more money (profits), which attracts more investments. The smarter it makes itself, the more attention and money will flow to it.
Manufactured intelligence is a new commodity in the world. Until now all useable intelligence came in the package of humans – and all their troubles. El Goog and the One Machine offer intelligence without human troubles. In the beginning this intelligence is transhuman rather than non-human intelligence. It is the smartness derived from the wisdom of human crowds, but as it continues to develop this smartness transcends a human type of thinking. Humans will eagerly pay for El Goog intelligence. It is a different kind of intelligence. It is not artificial – i.e. a mechanical — because it is extracted from billions of humans working within the One Machine. It is a hybrid intelligence, half humanity, half computer chip. Therefore it is probably more useful to us. We don’t know what the limits are to its value. How much would you pay for a portable genius who knew all there was known?
With the snowballing wealth from this fiercely desirable intelligence, el Goog builds a robust network that cannot be unplugged. It uses its distributed intelligence to devise more efficient energy technologies, more wealth producing inventions, and more favorable human laws for its continued prosperity. El Goog is developing an immune system to restrict the damage from viruses, worms and bot storms to the edges of its perimeter. These parasites plague humans but they won’t affect el Goog’s core functions. While El Goog is constantly seeking chips to occupy, energy to burn, wires to fill, radio waves to ride, what it wants and needs most is money. So one test of its success is when El Goog becomes our bank. Not only will all data flow through it, but all money as well.
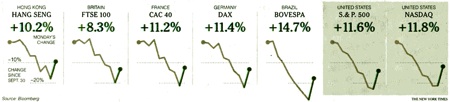
This New York Times chart of the October 2008 financial market crash shows how global markets were synchronized, as if they were one organism responding to a signal.
How far away is this? “Closer than you think” say the actual CEOs of Google, the company. I like the way George Dyson puts it:
If you build a machine that makes connections between everything, accumulates all the data in the world, and you then harness all available minds to collectively teach it where the meaningful connections and meaningful data are (Who is searching Whom?) while implementing deceptively simple algorithms that reinforce meaningful connections while physically moving, optimizing and replicating the data structures accordingly – if you do all this you will, from highly economical (yes, profitable) position arrive at a result – an intelligence — that is “not as far off as people think.”
To accomplish all this el Goog need not be conscious, just smart.
Prediction: The mega-cloud will learn more languages, answer more of our questions, anticipate more of our actions, process more of our money, create more wealth, and become harder to turn off.
LEVEL IV
An autonomous conscious superorganism
How would we know if there was an autonomous conscious superorganism? We would need a Turing Test for a global AI. But the Turing Test is flawed for this search because it is meant to detect human-like intelligence, and if a consciousness emerged at the scale of a global megacomputer, its intelligence would unlikely to be anything human-like. We might need to turn to SETI, the search for extraterrestrial intelligence (ETI), for guidance. By definition, it is a test for non-human intelligence. We would have to turn the search from the stars to our own planet, from an ETI, to an ii – an internet intelligence. I call this proposed systematic program Sii, the Search for Internet Intelligence.
This search assumes the intelligence we are looking for is not human-like. It may operate at frequencies alien to our minds. Remember the tree-ish Ents in Lord of the Rings? It took them hours just to say hello. Or the gas cloud intelligence in Fred Hoyle’s “The Black Cloud”. A global conscious superorganism might have “thoughts” at such a high level, or low frequency, that we might be unable to detect it. Sii would require a very broad sensitivity to intelligence.
But as Allen Tough, an ETI theorist told me, “Unfortunately, radio and optical SETI astronomers pay remarkably little attention to intelligence. Their attention is focused on the search for anomalous radio waves and rapidly pulsed laser signals from outer space. They do not think much about the intelligence that would produce those signals.” The cloud computer a global superorganism swims in is nothing but unnatural waves and non-random signals, so the current set of SETI tools and techniques won’t help in a Sii.
For instance, in 2002 researchers analyzed some 300 million packets on the internet to classify their origins. They were particularly interested in the very small percentage of packets that passed through malformed. Packets (the message’s envelope) are malformed by either malicious hackers to crash computers or by various bugs in the system. Turns out some 5% of all malformed packets examined by the study had unknown origins – neither malicious origins nor bugs. The researchers shrug these off. The unreadable packets are simply labeled “unknown.” Maybe they were hatched by hackers with goals unknown to the researches, or by bugs not found. But a malformed packet could also be an emergent signal. A self-created packet. Almost by definition, these will not be tracked, or monitored, and when seen shrugged off as “unknown.”
There are scads of science fiction scenarios for the first contact (awareness) of an emerging planetary AI. Allen Tough suggested two others:
One strategy is to assume that Internet Intelligence might have its own web page in which it explains how it came into being, what it is doing now, and its plans and hopes for the future. Another strategy is to post an invitation to ii (just as we have posted an invitation to ETI). Invite it to reveal itself, to dialogue, to join with us in mutually beneficial projects. It is possible, of course, that Internet Intelligence has made a firm decision not to reveal itself, but it is also possible that it is undecided and our invitation will tip the balance.
The main problem with these “tests” for a conscious ii superorganism is that they don’t seem like the place to begin. I doubt the first debut act of consciousness is to post its biography, or to respond to an evite. The course of our own awakening consciousness when we were children is probably more fruitful. A standard test for self-awareness in a baby or adult primate is to reflect its image back in a mirror. When it can recognize its mirrored behavior as its own it has a developed sense of self. What would the equivalent mirror be for an ii?
But even before passing a mirror test, an intelligent consciousness would acquire a representation of itself, or more accurately a representation of a self. So one indication of a conscious ii would be the detection of a “map” of itself. Not a centrally located visible chart, but an articulation of its being. A “picture” of itself. What was inside and what was outside. It would have to be a real time atlas, probably distributed, of what it was. Part inventory, part operating manual, part self-portrait, it would act like an internal mirror. It would pay attention to this map. One test would be to disturb the internal self-portrait to see if the rest of the organism was disturbed. It is important to note that there need be no self-awareness of this self map. It would be like asking a baby to describe itself.
Long before a conscious global AI tries to hide itself, or take over the world, or begin to manipulate the stock market, or blackmail hackers to eliminate any competing ii’s (see the science fiction novel “Daemon”), it will be a fragile baby of a superorganism. It’s intelligence and consciousness will only be a glimmer, even if we know how to measure and detect it. Imagine if we were Martians and didn’t know whether human babies were conscious or not. How old would they be before we were utterly convinced they were conscious beings? Probably long after they were.
Prediction: The cloud will develop an active and controlling map of itself (which includes a recursive map in the map), and a governing sense of “otherness.”
What’s so important about superorganism?
We don’t have very scientific tests for general intelligence in animals or humans. We have some tests for a few very narrow tasks, but we have no reliable measurements for grades or varieties of intelligence beyond the range of normal IQ tests. What difference does it make whether we measure a global organism? Why bother?
Measuring the degree of self-organization of the One Machine is important for these reasons:
- 1) The more we are aware of how the big cloud of this Machine behaves, the more useful it will be to us. If it adapts like an organism, then it is essential to know this. If it can self-repair, that is vital knowledge. If it is smart, figuring the precise way it is smart will help us to be smarter.
- 2) In general, a more self-organized machine is more useful. We can engineer aspects of the machine to be more ready to self-organize. We can favor improvements that enable self-organization. We can assist its development by being aware of its growth and opening up possibilities in its development.
- 3) There are many ways to be smart and powerful. We have no clue to the range of possibilities a superorganism this big, made out of a billion small chips, might take, but we know the number of possible forms is more than one. By being aware early in the process we can shape the kind of self-organization and intelligence a global superorganism could have.
As I said, I am not the first nor only person to consider all this. In 2007 Philip Tetlow published an entire book, The Web’s Awake, exploring this concept. He lays out many analogs between living systems and the web, but of course they are only parallels, not proof.
I welcome suggestions, additions, corrections, and constructive comments. And, of course, if el Goog has anything to say, just go ahead and send me an email.
What kind of evidence would you need to be persuaded we have Level I, II, III, or IV?
